
Table of Contents

Module 2 - Design the Network Structure
Section 5 - Select Routing and Bridging Protocols
Section Objectives
Upon completion of this section, you will be able to:
-
Identify scalability constraints and issues for IGRP, Enhanced IGRP, IP
RIP, IPX RIP/SAP, NLSP, AppleTalk RTMP and AURP, static routing, and bridging
protocols.
-
Recommend routing and bridging protocols that meet a customer's requirements
for performance, security, and capacity.
Time Required to Complete This Section
Approximately 2 hours
Completing This Section
Follow these steps to complete this section:
1. Study the reading assignment.
2. Click on any links that you see in the reading assignment and review
the information that appears.
3. Review any tables and job aids that appear in the reading assignment.
4. Review the case studies at the end of this section.
5. Complete the questions in each case study.
6. Review the answers provided by our internetworking experts.
Resources Required to Complete This Section
To complete this section, you will need:
-
Access to the World Wide Web and Cisco's Web site
-
A downloaded, printed copy of this section
-
Paper and pencil
Reading Assignment
Routing and Bridging Protocols
Routing protocols can be characterized by what information is exchanged
between routing peers. Protocols may:
-
Send periodic updates.
-
Have a separate hello mechanism.
-
Exchange information about links.
-
Exchange information about routes.
This section assumes you are familiar with the routing and bridging protocols
described. If you are not familiar with any of the protocols covered in
this section, install the Cisco Connection Training CD-ROM (part of your
student kit) and review the necessary information.
Link-State Protocols
Link-state protocol routers tell peers about directly connected links.
Generally, larger networks utilize link-state protocols, including:
-
OSPF
-
IS-IS
-
NetWare Link Services Protocol (NLSP)
With link-state routing protocols, the IP address space can be mapped so
that discontiguous subnets and variable-length subnet masks are supported.
The IP address space must be mapped carefully so that subnets are arranged
in contiguous blocks, allowing routing advertisements to be summarized
at area boundaries, which reduces the number of routes advertised throughout
the internetwork. If correctly configured, contiguous blocks of subnets
can be consolidated as a single route. Route summarization was discussed
in more detail in Section 4 of
this module.
When route summarization is not configured, links going up and down
generate many updates, causing a lot of traffic and router CPU overhead
as the link-state routers recalculate the topology. Links going up and
down is often called "link flapping," which means a link is intermittently
nonoperational. Link flapping can be caused by noise, misconfigurations
or reconfigurations, or hardware failures.
For a list of frequently asked questions about OSPF, click
here.
For information about how to design OSPF networks, read the OSPF
Design Guide.
Distance Vector Routing Protocols
Distance vector routers tell neighbors about all known routes. Generally
distance vector protocols are found in small- to medium-sized networks.
Distance vector routers can send the entire routing table or they can send
only updates. The following protocols are distance-vector routing protocols:
-
RIP
-
RIPv2
-
IGRP
-
AppleTalk RTMP
With distance vector routing, updates can be easily interpreted with a
protocol analyzer that makes debugging easy. Unfortunately, it also makes
it easy for a hacker to understand the protocol and compromise it.
When distance vector routing protocols are used, address consolidation
is automatic at subnet and network boundaries. For example, RIP and IGRP
always summarize routing information by major network numbers. They are
called classfull routing protocols because they always consider the IP
network class, which has important results:
-
Subnets are not advertised across a different major network.
-
Discontiguous subnets are not visible to each other.
-
Variable-length subnet masks are not supported.
Enhanced IGRP
Enhanced IGRP is a hybrid protocol that has attributes associated with
both distance vector and link-state protocols. You can use Enhanced IGRP
to create an "advanced" routing protocol. Enhanced IGRP can scale to hundreds
of routing nodes in an internetwork.
Enhanced IGRP also supports discontiguous subnets and variable-length
subnet masks. Like the link-state protocols, summarization of address blocks
with prefix routing must be manually configured.
In May 1996, Cisco introduced a new version of Enhanced IGRP. It was
incorporated into Cisco IOS Releases 10.3(11), 11.0(8), 11.1(3), 11.2(1),
and later releases and is compatible with older versions. Raja Sundaram
of Cisco's Technical Assistance Center (TAC) has written an excellent paper
that includes detailed information on the enhancements plus additional
detail on Enhanced IGRP in general.
Enhanced IGRP is an excellent choice when smaller networks connect to
larger networks. Running desktop routing protocols such as AppleTalk RTMP
or IPX RIP/SAP on the enterprise network is often not a good idea because
of the amount of traffic that these protocols cause. Running Enhanced IGRP
is especially not a good idea on slow serial links.
Enhanced IGRP has protocol-dependent modules that support routing for
IP, IPX, and AppleTalk. The IPX module also supports Novell SAP. Enhanced
IGRP works on the ships-in-the-night (SIN) model. Each client protocol
has its own separate hellos, timers, and metrics.
Enhanced IGRP automatically redistributes routing and SAP tables to
each client protocol. By default, Enhanced IGRP advertises full RIP, SAP,
and RTMP updates on LAN interfaces and reliable updates only on WAN interfaces.
Interior Routing Protocols
Routing protocols can also be characterized by where they are used. Interior
routing protocols, such as RIP, IGRP, and Enhanced IGRP, are used by routers
within the same autonomous system.
In some cases, it is not always necessary to use a routing protocol.
Static routes are often used to connect to a stub network. A stub network
is a part of an internetwork that can only be reached by one path. An example
of a stub network is an autonomous system that connects to the Internet.
If only one path exists to the autonomous system, routers in the Internet
can use static routing to reach the autonomous system. By not using a routing
protocol, bandwidth is conserved.
Routing Protocol Scalability Constraints
Scalability constraints for routing protocols can be characterized as follows:
Limits on Metrics
For example, no RIP-based internetwork can have a diameter greater than
15 hops.
Convergence Time
Link-state protocols tend to converge more quickly than distance vector
protocols.
Resource Requirements
-
How often routing updates are transmitted
-
A function of the update timer
-
Updates might be triggered by events
-
How much data is transmitted
-
The whole routing table or just changes
-
How widely routing updates are distributed
-
To neighbors
-
To a bounded area
-
To all routers in the autonomous system
-
How static and default routes are used
-
Whether route summarization is supported and how
NLSP
Another option for reducing routing traffic in a Novell environment is
to use the NLSP. NLSP only advertises routing and services incrementally.
It also has faster convergence than IPX RIP.
AURP
To reduce routing traffic in an AppleTalk environment, you can use AppleTalk
Update Routing Protocol (AURP). AURP is designed to handle routing update
traffic over WAN links more efficiently than RTMP. It does not replace
RTMP in the LAN environment.
AURP has many features:
-
Reduced routing traffic on WAN links because only updates are sent.
-
Tunneling through IP internetworks or other network systems.
-
Basic security, including device hiding and network hiding.
-
Remapping of remote network numbers to resolve numbering conflicts.
-
Internetwork clustering to minimize routing traffic and storage requirements.
-
Hop-count reduction to allow the creation of larger internetworks.
Bridging Protocols for Cisco Routers and Switches
Several types of bridging protocols are supported by Cisco routers (bridges)
and switches:
-
Transparent bridging is found primarily in Ethernet environments.
-
Source-route bridging is found primarily in Token Ring environments.
-
Translational bridging attempts to translate from Ethernet bridging to
Token Ring bridging.
-
Encapsulating bridging allows packets to cross a bridged backbone network.
-
Source-route transparent bridging allows a bridge to function as both a
source-routing and transparent bridge.
Transparent Bridging Scalability Issues
A transparent bridge floods all multicast/broadcast frames and frames with
an unknown destination address out every port except the port on which
the frame was received. Multicasts and broadcasts create a scalability
issue, as discussed in Section 2 of Module 1 and Section 2 of Module 2.
In the case of unknown addresses, a transparent bridge listens to all
frames and learns what port to use to reach devices. The bridge learns
by looking at the source address in all frames, so an unknown address becomes
a known address once a device has sent a frame. Scalability is an issue
if the bridge has a very limited number of addressees that it can learn
about. Cisco devices do not have severe limitations. Refer to product information
on Cisco's Web site for more detailed
information on limitations for Cisco devices.
Transparent bridges implement the spanning-tree algorithm, which is
specified in IEEE 802.1d. The spanning-tree algorithm states that there
is one and only one active path between two stations. The algorithm handles
loops by disabling bridge ports. Transparent bridges send Bridge Protocol
Data Unit (BPDU) frames to each other to build and maintain a spanning
tree. The spanning tree has one root bridge and a set of active bridge
ports, selected by determining the lowest-cost paths to the root bridge.
The BPDU frames are sent to a multicast address every two seconds. The
amount of traffic caused by BPDU frames can be a scalability issue on very
large flat networks with numerous switches or bridges.
Source-Route Bridging Scalability Issues
In Token Ring environments, source nodes as well as bridges and switches
must understand bridging. With source-route bridging, a source node finds
another node by sending explorer packets. Scalability is affected by the
type of explorer packet the source sends. An explorer packet can be one
of the following:
All-Routes Explorer
The source node specifies that the explorer packet should take all possible
paths. The source node usually specifies that the response should take
just one path back.
Singe-Route Explorer
The source node specifies that the explorer packet should take just one
path and that the response should take either all paths or just one path
back.
When single-route explorer packets are used, the bridges can use the spanning-tree
algorithm to determine a single path to the destination. If the spanning-tree
algorithm is not used, the network administrator must manually choose which
bridge should forward single-route explorers when there are multiple redundant
bridges connecting two rings.
The main scalability issue for source-route bridging, however, is the
amount of traffic that can arrive on the destination station's ring when
all-routes explorer packets are used. To reduce the amount of traffic on
the network:
-
Limit the size of flat bridged networks.
-
Introduce routers to segment the network.
-
If a non routable protocol such as NetBIOS is prevalent, investigate implementations
that support NetBIOS on top of a network-layer protocol such as IP or IPX.
Integrated Routing and Bridging (IRB)
For customers who need to merge bridged and routed networks, Cisco
IOS Release 11.2 has an integrated routing and bridging (IRB) feature
that interconnects VLANs and bridged domains to routed domains within the
same router. IRB provides the capability to route between bridged and routed
interfaces using a software-based interface called the Bridged Virtual
Interface (BVI).
Another advantage of IRB is that you gain the flexibility to extend
a bridge domain across a router's interfaces to provide a temporary solution
for moves, adds, and changes, which can be useful during migration from
a bridged environment to a routed environment.
IRB supports IP, IPX, and AppleTalk. IRB is supported for transparent
bridging, but not for source-route bridging. IRB is supported on all types
of interfaces except X.25 and ISDN bridged interfaces.
Characterizing Routing Protocols
The following tables will help you characterize routing protocols so you
can recommend routing protocols that will meet a customer's requirements
for performance, security, capacity, and scalability.
Calculating Bandwidth Used by Routing Protocols
|
Routing Protocol
|
Default Update Timer (Seconds)
|
Route Entry Size (Bytes)
|
Network and Update Overhead (Bytes)
|
Routes per Packet
|
| IP RIP |
30 |
20 |
32 |
25 |
| IP IGRP |
90 |
14 |
32 |
104 |
| AppleTalk RTMP |
10 |
6 |
17 |
97 |
| IPX SAP |
60 |
64 |
32 |
7 |
| IPX RIP |
60 |
8 |
32 |
50 |
| DECnet IV |
40 |
4 |
18 |
368 |
| VINES VRTP |
90 |
8 |
30 |
104 |
| XNS |
30 |
20 |
40 |
25 |
Notes:
AppleTalk: DDP = 13 bytes, RTMP = 4 bytes, each route update = 6 bytes,
maximum DDP data = 586. 586 - 4 = 582. 582/6 = 97 routes in a route update
packet.
NetWare: IPX RIP limits the number of routes in an update packet to
50. IPX SAP limits the number of SAPs in an update packet to seven. These
limits apply regardless of the maximum transmission unit (MTU).
IP RIP is limited to 50 routes per update, regardless of MTU.
Routing Protocol Administrative Distance
In some network designs, more than one IP routing protocol is configured.
If a router has more than two routes to a destination, the route with the
lowest administrative distance is placed in the routing table. The following
table shows the default administrative distances for IP routes learned
from different sources.
Administrative Distances for IP Routes
|
IP Route
|
Administrative Distance
|
| Connected interface |
0 |
| Static route using a connected interface |
0 |
| Static route using an IP address |
1 |
| Enhanced IGRP summary route |
5 |
| External BGP route |
20 |
| Internal Enhanced IGRP route |
90 |
| IGRP route |
100 |
| OSPF route |
110 |
| IS-IS route |
115 |
| RIP route |
120 |
| EGP route |
140 |
| External Enhanced IGRP route |
170 |
| Internal BGP route |
200 |
| Route of unknown origin |
255 |
Cisco IOS software also supports "floating static route," which is a
static route that has a higher administrative distance than a dynamically
learned route. Floating static routes are available for IP, IPX, and AppleTalk.
Static routes are traditionally implemented so they always take precedence
over any dynamically learned routes to the same destination network. A
floating static route is a statically configured route that can be overridden
by dynamically learned routing information. Thus, a floating static route
can be used to create a "path of last resort" that is used only when no
dynamic information is available.
One important application of floating static routes is to provide backup
routes in topologies where dial-on-demand (DDR) routing is used.
Routing Protocols Convergence
Convergence is the time it takes for routers to arrive at a consistent
understanding of the internetwork topology after a change takes place.
Packets may not be reliably routed to all destinations until convergence
takes place. Convergence is a critical design constraint for some applications.
For example, convergence is critical when a time-sensitive protocol such
as SNA is transported in IP packets.
Convergence depends on:
-
Timers
-
Network diameter and complexity
-
Frequency of routing protocol updates
-
Features of the routing protocol
In general, Enhanced IGRP and the link-state protocols converge faster
than distance vector protocols.
Convergence has two components:
-
The time it takes to detect the link failure
-
Time to determine a new route
The following table indicates the time required by the interface to detect
a link failure and the action taken by the routing protocols.
Time to Detect Link Failure
| Serial lines |
Immediate if Carrier Detect (CD) lead drops |
| |
Otherwise, between two and three keepalive times |
| |
Keepalive timer is ten seconds by default |
| Token Ring or FDDI |
Almost immediate due to beacon protocol |
| Ethernet |
Between two and three keepalive times |
| |
Keepalive timer is ten seconds by default |
| |
Immediate if caused by local or transceiver failure |
IGRP Convergence Steps
1. Link failure is detected
2. Router sends a triggered update, indicating unreachable networks:
-
Sent immediately to adjacent routers
-
Adjacent routers generate triggered updates in turn
3. Routers continue to send routing table at the normal update interval:
-
Might coincide with the triggered updates
-
Hold-down timer (default = 280 seconds) allows information to stabilize
Enhanced IGRP Convergence Steps
1. Link failure is detected.
2. The router looks at local and neighbor routing tables for an alternate
route.
3. The router switches to alternate route immediately if found locally.
4. The router sends query to neighbors if no alternate route is found
locally.
5. The query propagates until a new route is found.
6. Affected routers update their routing tables.
OSPF Convergence Steps
1. Link failure is detected.
2. Routers exchange routing information and build a new routing table.
3. Built-in delay of 5 seconds prevents rapid changes from causing unstable
routing.
Distance Vector Topology Changes
When the topology in a distance vector protocol
internetwork changes, routing table updates must occur. As with the network
discovery process, topology change updates proceed step-by-step from router
to router.

Distance vector algorithms call for each
router to send its entire routing table to each of its adjacent neighbors.
Distance vector routing tables include information about the total path
cost (defined by its metric) and the logical address of the first router
on the path to each network it knows about.
When a router receives an update from a
neighboring router, it compares the update to its own routing table. If
it learns about a better route (smaller metric) to a network from its neighbor,
the router updates its own routing table. In updating its own table, the
router adds the cost of reaching the neighbor router to the path cost reported
by the neighbor to establish the new metric.
For example, if Router B in the graphic
is one unit of cost from Router A, Router B would add 1 to all costs reported
by Router A when it runs the distance vector processes needed to update
its routing table.
Problem: Routing Loops
Routing loops can occur if the internetworks
slow convergence on a new configuration causes inconsistent routing entries.
The following graphic illustrates how a routing loop can occur:
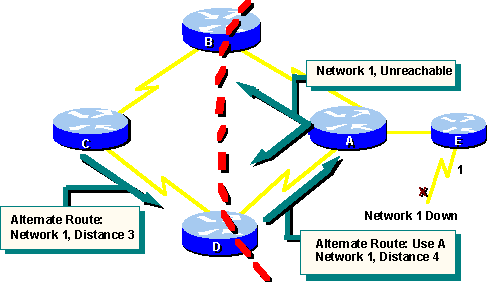
Just before the failure of network 1, all
routers have consistent knowledge and correct routing tables. The network
is said to have converged. Assume for the remainder of this example that
Router Cs preferred path to network 1 is by way of Router B, and Router
C has a distance of 3 to Network 1 in its routing table.
When Network 1 fails, Router E sends an
update to Router A. Router A stops routing packets to network 1, but Routers
B, C, and D continue to do so because they have not yet been informed about
the failure. When Router A sends out its update, Routers B and D stop routing
to Network 1. However, Router C is still not updated. To Router C, Network
1 is still reachable via router B.
Now Router C sends a periodic update to
Router D, indicating a path to network 1 by way of Router B. Router D changes
its routing table to reflect this good, but erroneous, news and propagates
the information to router A. Router A propagates the information to Routers
B and E, and so on. Any packet destined for Network 1 will now loop from
Router C to B to A to D and back to C.
Problem: Counting to Infinity
Continuing our previous example, the invalid
updates about Network 1 continue to loop. Until some other process can
stop the looping, the routers update each other in an inappropriate way,
considering the fact that Network 1 is down.

This condition, called count-to-infinity,
continuously loops packets around the network, despite the fundamental
fact that the destination Network 1 is down. While the routers are counting
to infinity, the invalid information allows a routing loop to exist.
Without countermeasures to stop the process,
the distance vector of hop count increments each time the packet passes
through another router. These packets loop through the network because
of wrong information in the routing tables.
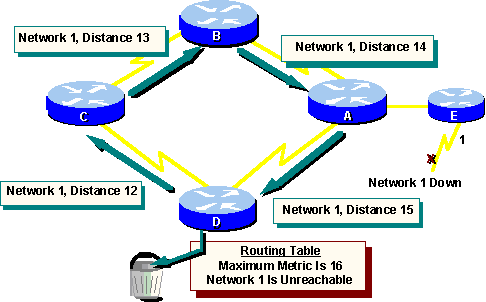
Solution: Defining a Maximum
Distance vector routing algorithms are self-correcting,
but the routing loop problem can require a count to infinity first.
To avoid this prolonged problem, distance
vector protocols define infinity as some maximum number. This number refers
to a routing metric (for example, a simple hop count).
With this approach, the routing protocol
permits the routing loop until the metric exceeds its maximum allowed value.
The following graphic shows this defined
maximum as 16 hops. For hop-count distance vectors, a maximum of 15 hops
is commonly used. In any case, once the metric value exceeds the maximum,
Network 1 is considered unreachable.
Solution: Split Horizon
A possible source for a routing loop occurs
when incorrect information sent back to a router contradicts the correct
information it sent. Here is how this problem occurs:
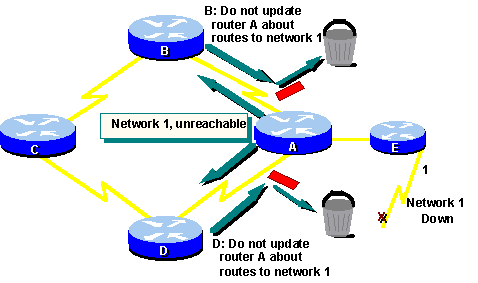
Router A passes an update to Router B and
Router D indicating that Network 1 is down. However, Router C transmits
an update to Router B indicating thatNetwork 1 is available at a distance
of 4 by way of Router D. This situation does not violate split-horizon
rules.
Router B concludes (incorrectly) that Router
C still has a valid path to Network 1, although at a much less favorable
metric. Router B sends an update to Router A advising A of the "new" route
to Network 1.
Router A now determines it can send to
Network 1 by way of Router B; Router B determines it can send to Network
1 by way of Router C; and Router C discerns it can send to Network 1 by
way of Router D. Any packet introduced into this environment will loop
between routers.
Split horizon attempts to avoid this situation.
As shown in the previous graphic, if a table update about Network 1 arrives
from Router A, Router B or D cannot send information about Network 1 back
to Router A. Split horizon thus reduces incorrect routing information and
reduces routing overhead.
Solution: Hold-Down Timers
You can avoid the count-to-infinity problem
by using hold-down timers, which work as follows:
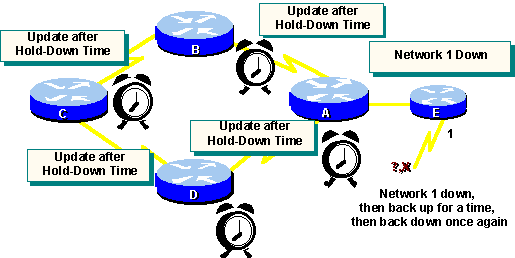
When a router receives an update from a neighbor
indicating that a previously accessible network is now inaccessible, the
router marks the route as inaccessible and starts a hold-down timer. If
at any time before the hold-down timer expires, an update is received from
the same neighbor indicating that the network is again accessible, the
router marks the network as accessible and removes the hold-down timer.
If an update arrives from a different neighboring
router with a better metric than originally recorded for the network, the
router marks the network as accessible and removes the hold-down timer.
If at any time before the hold-down timer
expires, an update is received from a different neighboring router with
a poorer metric, the update is ignored. Ignoring an update with a poorer
metric when a hold-down is in effect allows more time for the knowledge
of a disruptive change to propagate through the entire network.
Matching Test
Following are 12 statements about scalability constraints for routing protocols.
Each statement refers to a specific routing protocol. Read the statement
and then select the routing protocol by clicking on the pull-down menu
and releasing the mouse button when the correct routing protocol is highlighted.
1. This protocol sends routing updates every
10 seconds, which can consume a large percentage of the
bandwidth on slow
serial links.
2. This protocol limits the number of networks
in a routing table update to 50, which means in a large
internetwork many
packets are required to send the routing table.
3. This protocol does not support discontiguous
subnets or variable-length subnet masks.
4. This protocol can advertise seven services
per packet, which causes many packets on enterprise
internetworks with
hundreds of services.
5. This protocol uses 14 bytes to define a route
entry, so it can send 104 routes in a 1500-byte packet.
6. This protocol should be recommended in hub-and-spoke
topologies with low bandwidth even though
it can be hard to
maintain because it is not dynamic.
7. This protocol is similar to OSI's IS-IS protocol
except that a hierarchical topology was not defined
until Version 1.1
of the routing protocol was specified (which is supported in Cisco IOS
Release 11.1).
8. This protocol supports route summarization
but it must be configured. It is not automatic. When route
summarization is not
configured, if link flapping occurs, a stream of updates is generated,
causing serious
traffic and router
CPU overhead.
9. If a customer is looking for ways to reduce
WAN routing traffic and is also considering tunneling in IP,
you could recommend
this protocol.
10. This protocol can be compromised because the routing
updates are easy to read with a protocol
analyzer and
an unsophisticated hacker can send invalid routing updates that routers
will accept.
11. Cisco refined the implementation of this protocol
in May 1996 to increase stability in environments
with many low-speed
links in NBMA WANs such as Frame Relay, ATM, or X.25 backbones, and in
highly redundant
dense router-router peering configurations.
12. If a customer wants a protocol with fast convergence
that can scale to hundreds of networks, and that
will fit
well with a hierarchical topology, you should recommend this protocol.
If you miss more than two questions you may want to review the protocol
information on the Cisco Connection Training CD-ROM (part of your student
kit).
The answers are available here.
If you want to view the case study and the solutions at the same time,
open a new browser window, so you can view two windows at the same time.
Case Studies
In this section, you will select a routing protocol for each of the
case studies.
Read each case study and complete the questions that follow. Keep in
mind that there are potentially several correct answers to each question.
When you complete each question, you can refer to the solutions provided
by our internetworking experts. The case studies and solutions will help
prepare you for the Sylvan exam following the course.
In this section, you will review the following case studies:
1. CareTaker Publications, a publishing company
2. PH Network Services Corporation, a health care company
3. Pretty Paper Ltd., a European wall covering company
4. Jones, Jones, & Jones, an international law firm
Case Study: CareTaker Publications
Remember CareTaker Publications? If not, click
here to review the case study.
You might find it useful to refer to your topology diagram for CareTaker
Publications in Section 3.
1. The corporate Network Operations people
from the parent corporation will be in town and the IS
manager has asked
you to meet with her to describe how your IP addressing scheme will work
and
how it will interface
with the corporate network and the Internet. What routing protocol would
you
implement on the WAN
between CareTaker and the corporate Cisco 7000 series router?
2. Are there any protocols between corporate and
CareTakers facilities that cannot be routed?
3. What routing protocol is the most efficient
between the warehouse and CareTakers facilities?
4. Assuming the routing protocol between CareTaker
and HI is IGRP, what additional parameter
must you know before
the main office router can be configured for IGRP?
Now that you have completed the exercise, click here
to view the solutions provided by our internetworking design experts.
Case Study: PH Network Services Corporation
Remember PH Network Services Corporation? If not, click
here to review the case study.
You might find it useful to refer to your topology diagram created for
PH Network Services Corporation in Section 3.
1. Are there any protocols between PHs facilities
that cannot be routed?
2. Each hospital will be using existing routers
that are not necessarily Cisco routers. Which routing protocol
will be the most efficient
to implement between the PH Network Services network and the hospitals?
3. Which routing protocol would you select to
support the doctor offices dialing in via ISDN to the PH
Network Services network?
Now that you have completed the exercise, click here
to view the solutions of our internetworking design experts.
Case Study: Pretty Paper Ltd.
Remember Pretty Paper? If not, click here
to review the case study.
You might find it useful to refer to your topology diagram created for
Pretty Paper in Section 3.
1. Are there any protocols between the facilities
that cannot be routed?
2. Who will you contact to determine which protocol
to use for the router to provide Internet connectivity?
3. Because all the remote sites have Cisco routers
attached to the WAN, which routing protocol is the
most efficient for
implementation?
Now that you have completed the exercise, click here
to view the solutions provided by our internetworking design experts.
Case Study: Jones, Jones, & Jones
Remember Mr. Jones? If not, click here
to review the case study.
You might find it useful to refer to your topology diagram created for
Mr. Jones in Section 3.
1. Are there any protocols between facilities
that cannot be routed?
2. Because all the remote sites have Cisco routers
attached to the WAN, which routing protocol is the
most efficient for
implementation?
3. Who will you contact to determine which protocol
to use for the router to provide Internet connectivity?
4. Which routing protocol would you select to
support the remote PCs dialing in via asynchronous/ISDN
to the local offices
network?
Now that you have completed the exercise, click here
to view the solutions provided by our internetworking design experts.
Click here to go on to Module 2, Section
6.
Copyright Cisco Systems, Inc. -- Version 2.0 7/98
